
- Mohammad Abudayyeh - Director of DevOps @ Gluu
Multi-Master Multi-Cluster LDAP (OpenDJ) replication in Kubernetes? A controversial view
OpenDJ is a Lightweight Directory Access Protocol (LDAP) compliant distributed directory written in Java. Many organizations use it as a persistence mechanism for their IAM systems. But should it be used in a multi cluster or multi regional Kubernetes setup by organizations? That is exactly what we want to discuss and dive into.Beware the initial YES
Gluu Federation had great results with OpenDJ working in a multi-AZ single Kubernetes cluster. As a result, Gluu Federation decided that the engineering team should take on the task of supporting multi-regional OpenDJ in Kubernetes setups. We realized that OpenDJ needed a lot of work. The containerization team looked at one of the most probable issues that would arise, which are replication issues. Looking at the code, OpenDJ lacked a lot of the networking smarts that would ease the addition and removal of regional pods. The solution was to match Serf with our OpenDJ container image and use it as the intelligence layer for pod membership, OpenDJ pod failure detection, and orchestration. That layer would communicate effectively with the replication process OpenDJ holds through NodePorts or static addresses assigned per pod.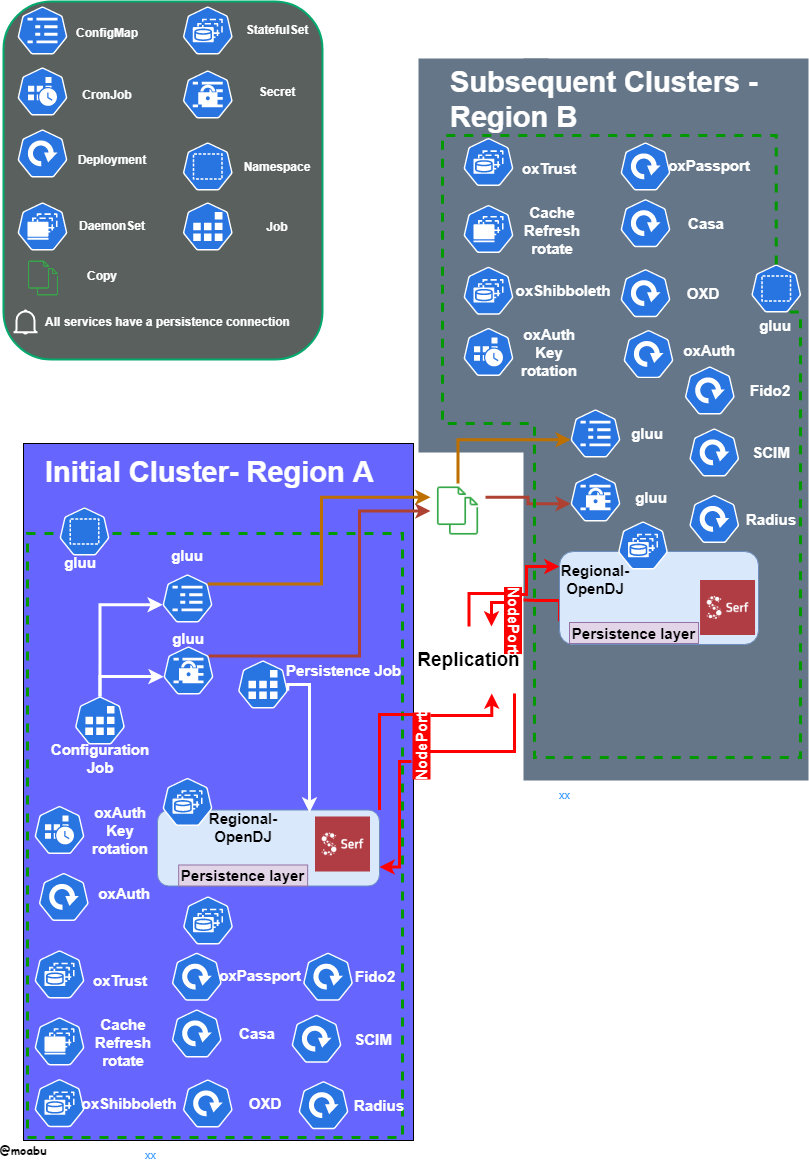
OpenDJ communication
Gluu Federation helm charts holding the OpenDJ sub chart also took care of creating the needed Kubernetes resources to support a multi-regional setup. After several rounds of testing
Gluu rolled it out in Alpha stage to some customers. Although the solution worked we started noticing several issues:
Replication! Depending on how fast replications occurs and the user login rate, users may face login issues. Yes, this may occur in a single regional Kubernetes cluster but it is much less observable. To solve this, the user needed to be tied with a session and later reconcile the replication. Unless the user travels to another region before replication fully re balances that user won’t notice.
Missing Changes (M.C)! This was the main reason
Gluu Federation decided to withdraw the alpha support and remove the layers to support multi regional multi master OpenDJ setups in Kubernetes. Several missing changes started appearing in the long run that would not sync in. This would require manual intervention to force the sync and activate the replication correctly. Something many don’t want to be handling in a production environment. The below is one said replication status:
Suffix DN : Server : Entries : Replication enabled : DS ID : RS ID : RS Port (1) : M.C. (2) : A.O.M.C. (3) : Security (4)
----------:--------------------------------------------------------------:---------:---------------------:-------:-------:-------------:----------:--------------:-------------
o=gluu : gluu-opendj-east-regional-0-regional.gluu.org:30410 : 68816 : true : 30177 : 21360 : 30910 : 0 : : true
o=gluu : gluu-opendj-east-regional-1-regional.gluu.org:30440 : 66444 : true : 13115 : 26513 : 30940 : 0 : : true
o=gluu : gluu-opendj-west-regional-0-regional.gluu.org:30441 : 67166 : true : 16317 : 17418 : 30941 : 0 : : true
o=metric : gluu-opendj-east-regional-0-regional.gluu.org:30410 : 30441 : true : 30271 : 21360 : 30910 : 0 : : true
o=metric : gluu-opendj-east-regional-1-regional.gluu.org:30440 : 24966 : true : 30969 : 26513 : 30940 : 0 : : true
o=metric : gluu-opendj-west-regional-0-regional.gluu.org:30441 : 30437 : true : 1052 : 17418 : 30941 : 0 : : true
o=site : gluu-opendj-east-regional-0-regional.gluu.org:30410 : 133579 : true : 1683 : 21360 : 30910 : 0 : : true
o=site : gluu-opendj-east-regional-1-regional.gluu.org:30440 : 133425 : true : 15095 : 26513 : 30940 : 0 : : true
o=site : gluu-opendj-west-regional-0-regional.gluu.org:30441 : 133390 : true : 26248 : 17418 : 30941 : 0 : : true
Maintenance! No matter how good of a solution it was it required constant care unlike modern central managed NOSQL or even RDBMS solutions.
Recovery! Not as easy as thought , but recovery can go wrong easily since the operations are occurring on an ephemeral environment. Sometimes this requires shutting down a regions persistence and preform the recovery on one side then bringing the subsequent region afterwards. Not so cloud friendly right?!
Cost! Taking a look at the cost organizations spend on just holding a setup as mentioned up is actually higher then simply using a cloud managed solution. Of course given that the cloud managed solution is viable as some organizations require all services to live on their data centers.
Scale! No matter how smart the solution was, scaling up and down on higher rates of authentications was an issue. Going back to the first issue mentioned, if a high surge occurred and replication was behind a bit some authentications will fail. What would happen if auto scaling was enabled and a high surge occurred? Obviously, the number of pods would increase and hence the number of available members that need to join OpenDJ increases.
While pods become ready to accept traffic several users will be directed to different pods depending on the routing strategy creating a bigger gap for replication differences to arise. If the surge discontinues before replication fully balances two scenarios may occur. The first is the normal wanted behavior where the pod would check if replication with its peers is perfect and there are no missing changes in which the pod de-registers itself from the cluster membership and then gracefully shuts down.
The other behavior is where a missing change arises and the pod can’t scale down hence holding up the resources until an engineer can walk in, look at the issue, fix it and possibly forcefully scale down. I’m not saying a solution can’t be made here but the price for making it available doesn’t make sense with more viable solutions such as RDBMS and NOSQL solutions.
Performance! In general, we noticed that any organization requiring larger then 200–300 authentications per second should avoid using OpenDJ as the persistence layer. You do not want to be handling replications issues with 200 authentications per second coming in.
Conclusion
I personally still love OpenDJ and the LDAP protocol in general but is it a cloud friendly product? Not really. I would still recommend it for single multi AZ Kubernetes cluster for small — medium organizations that are trying to save money and have a light load. Focusing on what matters for your organization is very important. If you can implement a central managed solution, and the cost for you is relatively low, you should go with a managed solution that can scale and replicate with minimal effort across regions.
